So let’s say you’re wasting time on a Saturday night (as one does) clicking on t.co links tweeted by people you pretend to know and love (hoping that the t(a)co url server hasn’t gone belly up as it is wont to do). And you happen to click on an article that by the time you make it through the third sentence you begin to question the hyperlink curation abilities of your so-called social media tweeps and decide that viewing the page source would be more interesting.
(That would be approximately right now, if you’re keeping score. Feel free to bounce or view-source or whatever.)
Believe it or not, this very same thing happened to me. A shocking hypothetical coincidence!
These days I use the Firefox web browser, which since version 11 has a nifty feature built into its view-source source viewer: it will report (nearly all) HTML5 parsing errors, and even give you a tool-tip ‘splainin what happened.
So let’s have a look at a screenshot of the fascinating things lying beneath that subjectively less than fascinating blog post. The good stuff is in red.
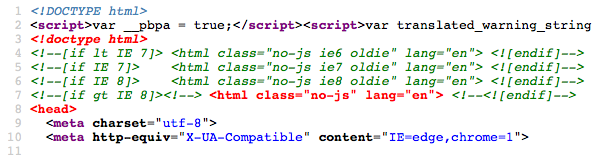
And here’s a simplified version with the errors denoted by the ⭕ (you know, U+2B55 HEAVY LARGE CIRCLE). Or maybe it’s an EMPTY NOT SO LARGISH SQUARE or one of these crazy guys � if that emoji didn’t come through for you. (I literally have no way of predicting what kind of tin can you’ll be looking at this blog post with.)
<!DOCTYPE html>
<script>var weird_code;</script>
<!doctype html> ⭕ Stray doctype.
<!-- (P. Irish conditional IE) comment (spam) -->
<html> ⭕ Stray start tag "html".
<head> ⭕ An "head" start tag seen but an element of the same type was
already open.
So what’s going on here? The 2nd doctype getting a stray doctype error makes a whole lotta sense. But how are the <html> and <head> tags stray or already opened, respectively? Pretty sure I only count one of each.
Now is a good time to go back and read the tree construction section of how HTML documents are parsed. Maybe read the rest if you’ve got a deathwish. Starting from the “initial” insertion mode, I’m just going to paraphrase what happens (without even attempting to explain what an insertion mode is, ha!).
“initial” insertion mode: If you find a valid doctype, switch to the “before html” insertion mode. If not, flip on quirks mode and switch to the “before html” insertion mode anyways. So far so good, our first token <!DOCTYPE html> is legit.
“before html” insertion mode: For the next token we actually hop to the last step (“Anything else”) of this mode because it isn’t a doctype, comment, whitespace, <html> start tag, </head>, </body>, </br>, </html>, or any other end tag. It’s a <script> start tag (dramatic squirrel)! So we have to create an <html> element (with no attributes), throw that bad boy on our open element stack, and then hop to the “before head” insertion mode and reprocess the <script> again. Jeeze.
“before head” insertion mode: Again, back to the “Anything else” escape hatch. We create a <head> start tag token and jump to the “in head” insertion mode and try to figure out what to do with this <script>.
“in head” insertion mode: <script>s belong in <head>s, so finally we get to somewhere where we can process the script move right along to the next token in our document.
By the 2nd line we’ve already created an <html> element and opened the <head> tag. And if there aren’t some lightbulbs going off in your head, dear reader, we’ve got a problem. But let’s keep going anyways, because I’m getting paid by the word here (feel free to click on some of our sponsor’s links too).
Remember that we’re in the “in head” insertion mode. The next token (the 3rd line) is one of them fancy lowercased HTML5 doctypes, which just happens to be a parse error in this mode. So we ignore it and move to the next line. Moving along, comments are OK (even the verbose hacky H5BP style ones), so we create some comment nodes from the comment tokens. The next line is <html>, which not surprisingly, given our insertion mode, calls for a parse error. But we actually have to jump to the…
“in body” insertion mode(:) to find that out. Now we have to add any attributes (class and lang in our example) and their values to our already existing html element. And finally, when “in body” a starting <head> tag token is an ignorable parse error.
You’re this far down the HTML parsing rabbit hole when you look at the clock and realize, man, there’s barely anything left of Saturday no thanks to you sloppy Tumblr theme designer.